Contents
- 1 Team Members
- 2 Mentor
- 3 Concept
- 4 Softwares Used
- 5 circuits
- 6 Algorithm for silence & noise removal
- 7 Codebook Formation
- 8 Testing isolated words using the Codebook
- 9 matlab & C coding
- 10 Memory organization
- 11 Current Achievements
- 12 Codes
- 13 working videos
- 14 References
Team Members
Aman Mangal
Rahul Prajapat
Namrata Singh
Mentor
Husain Manasawala
Concept
Our project is aimed at making a speaker independent speech recognition system.The system will take an input speech signal from a user. After silence/noise removal,it will compare the signal with every entry in an already stored code book ,to recognize the word said.
Softwares Used
- Matlab
- Arduino
circuits
Working
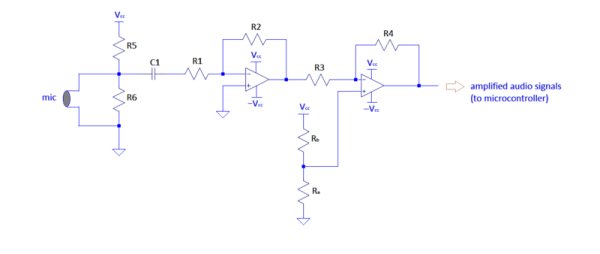
We are using electret condenser microphone for our project purpose. Input signals from microphone are pretty low, they need to be amplified before recognition (before going into arduino). Pre amp circuit for audio signals can be designed by any of the following op-amps LF353, LM358, LM741, LMC711 etc. We designed our circuit using LF353 which requires -5V and +5V. We are using atmega328 (arduino uno) for further processing. It accepts the values between 0 to 3.4V,at the input pin. Hence we want our peak to peak amplified audio signals in this range. The audio signals from microphone are in range of -0.005V to 0.005V as we checked through oscilloscope.
Now, we want output of circuit in range [0,3.4V] for an input range [-0.005V,0.005V]. Hence total gain of circuit should be about 340. The op- amps are in negative feedback loops and are inverting, so have a gain of R2/R1. So the total gain of the circuit is R2*R4/R1*R3 (=340). By doing experiments, it is convenient to take gain of first stage = 100 and gain of second amplifying stage = 3.4 .
Choosing resistances values accordingly:- R1=1K, R2=100K, R3=1K, R4=3.4K.
For dc bias, we simply put the positive terminal of first op-amp at GND and gave 0.5V at positive terminal of 2nd op-amp by resister divider circuit. Hence, we got final amplified signals in range of [0,3.4V].
EEPROM circuit
We are using 25LC1024 EEPROM[1] to store the data. It is based on 1 Mbit SPI Bus Serial communication. EEPROM pins are connected to Arduino pins as follows-
EEPROM pins 3 and 4 to ground.
EEPROM pins 7 and 8 to 5v
EEPROM pin 1 to Arduino pin 10 (Slave Select – SS),
EEPROM pin 2 to Arduino pin 12 (Master In Slave Out -MISO),
EEPROM pin 5 to Arduino pin 11 (Master Out Slave In – MOSI),
EEPROM pin 6 to Arduino pin 13 (Serial Clock – SCK).
Led Matrix display circuit
We have chosen to show our output on an led matrix, such that whenever the user speaks some number ,the corresponding number gets displayed on the led matrix.Similarly,when the user says yes a tick is dispalyed while a cross is displayed for a no.For other commands like left,right,forward,backward an arrow is shown in the corresponding direction.
Algorithm for silence & noise removal
Pre-Emphasis
Human Voice mostly has the characteristic that the lower frequencies have higher amplitudes,while the higher frequencies are spoken with a relatively smaller amplitude.As a result,the higher frequencies have high chances to be swept away as a noise during the noise removal procedure.Hence to emphasize the high frequency contents,we carry out pre-emphasis,which increases the signal-to-noise ratio. Let x be the input sound signal and y be the result after pre-emphasis,n] = x[n] – 0.97x[n-1];
where the coefficient 0.97 depends upon the order of FIR filter used. Hereafter,the speech signal is sent for noise-removal.
Silence and Noise Removal
Idea
Firstly we needed to isolate the recorded spoken word from the surrounding noise as well as silence.We assumed that the unvoiced/silence part of a speech signal has a waveform that is aperiodic or random in nature,whereas the voiced part of a speech signal is periodic in nature.Central Limit Theorem states that, under various conditions, the distribution for the sum of the independent random variables approaches a particular limiting form known as the normal distribution. Usually first 200 msec or more (1600 samples if the sampling rate is 8000 samples/sec) of a speech recording corresponds to silence because the speaker takes some time to speak when the recording starts.Hence according to the central limit theorem,all the unvoiced/silence part of the speech signal will follow a normal distribution with a mean mu and standard deviation sigma, where mu is the mean of the first 200msec of the speech while sigma is the standard deviation of the same.In a normal distribution,99% of the data lies at distance of 3*sigma from the mean,while 95% of the data lies at a distance of 2*sigma and around 68% of the data lies at distance of sigma from the mean. Mathematically,
We have used this property of normal distribution to eliminate noise from the speech signal.
Implementation
Hence,if x be one speech sample in the speech signal then we know that if it is unvoiced, it will lie at a distance of 3sigma from the mean for 99% of the times.Hence if the one dimensional Mahalanobis distance[2] of x from the mean is lesser than 3,we can assert with 99% surity that the speech sample is noise. Mathematically,l) = |x-mu|/sigma;
Hereafter,the speech sample recognized as a noise is marked 0,while that recognized as voice is marked 1.We then divide the resulting array of either zeroes or ones into non-overlapping windows of 10msec length(80 samples if the sampling frequency is 8000Hz). All the samples in a particular window are then assigned either one or zero depending on if there are higher number of ones or zeroes in that window.The voiced part is retrieved by selecting only the windows which are marked all ones.
Codebook Formation
A Codebook is like a set of data fed to the system,which it uses to compare with an input speech signal to recognize the spoken word.
Database
Database is the input taken for the codebook formation,which is otherwise taken from the user during Word Recognition.Our database consists of four utterances of each word, for a group of words to be recognized. We carried out experiments using different number of utterances for each word and found that the algorithm was working the best for four.
Main Algorithm
The trickiest part of our project was to form a codebook which would contain a series of vectors which would closely resemble the word spoken in their respective categories, for at least 90% of the times!We have used DWT(Discrete Wavelet Transform)[3] for wavelet feature extraction and kmeans algorithm[4] for segregation of the vectors into clusters representing a particular type of word spoken.
Common Procedure
Some part of the algorithm is same for codebook formation and also word recognition.An input speech signal is obtained, sampled at a frequency of 16000Hz ,is obtained from the microphone. Post de-noising(discussed above), it is first de-emphasized(this together with pre-emphasis is called emphasis) and then normalized.
Normalization
Normalization of the speech signal simply scales all the values to the range of -1 to 1.This is done to check that volume of the speaker does not affect the analysis. 1 is a sound signal obtained after de-emphasis
After normalization,the sound signal is buffered into three groups ,of equal length, with 33% overlap.This means that the sound signal is divided into three groups of identical length,such that the overlap in between successive frames is 33%.i.e they share 33% values in common. If the sound signal is of length 2L,then the first buffer runs from one to 6*L/7,the second buffer runs from 4*L/7 to 10*L/7 and the thirs one runs from 8*L/7 to 2L .Hence each buffer has an approximate length of 6*L/7.
For more detail: Voice Recognition System